

Log analysis in software applications involves collecting, parsing, and interpreting these logs to extract meaningful information. By analyzing logs, organizations can detect errors, identify potential security threats, monitor user activities, and ensure compliance with regulations. The goal of log analysis is to turn raw data into actionable insights that can drive decision-making and enhance system reliability and security.
Whether you are managing a small application or a large-scale distributed system, log analysis provides valuable insights that help you keep everything running smoothly. In this blog post, we will explore the basics of log analysis, using an AWS service named OpenSearch Serverless.
What Is Amazon OpenSearch Serverless?
Amazon OpenSearch Serverless is a fully managed, serverless service designed for search and analytics, built on OpenSearch, an open-source project derived from the final open-source version of Elasticsearch. It offers scalable solutions to handle large data volumes without requiring users to provision, manage, or scale clusters manually.
With OpenSearch Serverless, compute and memory resources are automatically scaled to meet the demands of data processing and querying, allowing users to pay only for the resources they actually use. This approach streamlines the deployment and management of search and analytics tasks, offering a flexible environment that adjusts to the size and complexity of the data.
Primary Use Cases for OpenSearch Serverless
OpenSearch Serverless can be used for the following tasks.
Log Analytics
Amazon OpenSearch Serverless is designed to handle log analytics efficiently. This includes collecting, monitoring, and analyzing system and application logs at scale. By leveraging serverless technology, it automatically scales according to the volume of data, managing changing workloads without the need for manual intervention.
Organizations can ingest logs directly from various sources like AWS CloudTrail, Amazon VPC Flow Logs, and custom application logs. This process simplifies the management and analysis of large volumes of log data.
Full-Text Search
OpenSearch Serverless supports full-text search capabilities, allowing businesses to easily implement search functionality within their applications or websites. It enables complex search queries, including fuzzy matching, auto-completion, and synonym searching.
The serverless nature of the service ensures that it scales automatically to handle growth in data volumes without manual scaling or management. This feature significantly reduces the operational burden and costs associated with managing a large-scale search infrastructure.
How Amazon OpenSearch Serverless Operates
Decoupling Ingest and Query Functions
Amazon OpenSearch Serverless is built with a cloud-native structure, distinct from traditional OpenSearch clusters. Typically, a single cluster would handle both data ingestion and search queries, with storage closely linked to the computing power. However, as data size and query demand increase, this setup can become inefficient.
In OpenSearch Serverless, ingestion and query processes are split into separate components. Data indexing is handled independently from search operations, with Amazon S3 used as the primary storage location for indexes. This allows each function to scale individually, optimizing resource utilization.
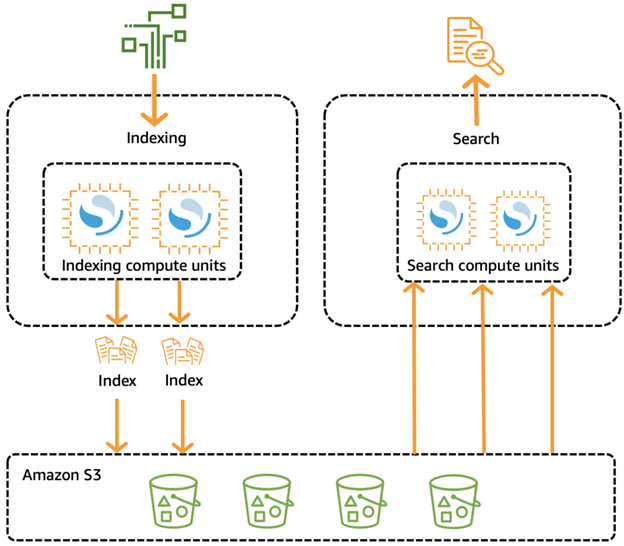
Source: AWS
{kind=link}
OpenSearch Compute Units (OCUs)
When data is added to a collection in OpenSearch Serverless, it is distributed across compute units dedicated to indexing. These units process the data and store the resulting indexes in Amazon S3.
For search queries, OpenSearch Serverless routes them to specialized search compute units. These units retrieve indexed data from S3 or cached copies and execute the search operations, delivering results efficiently. This design supports high-performance searches without the constraints of traditional infrastructure.
OCUs represent the basic compute capacity for both ingestion and querying tasks. Each OCU includes 6 GiB of memory, a virtual CPU (vCPU), and supports data transfer to and from Amazon S3, with ephemeral storage for up to 120 GiB of index data. As collections increase, OpenSearch Serverless dynamically scales OCUs to match workload demands.
OpenSearch Serverless Collection Types
Types of OpenSearch Serverless Collections
- Time Series
Time series collections are designed for analyzing time-stamped data like metrics, events, or logs. They offer efficient handling of sequential time series data for real-time monitoring and historical analysis, helping organizations detect trends or anomalies over time - Search
Search collections support a wide range of search needs, from basic text searches to more complex queries. Designed for speed and accuracy, these collections include features like keyword searches, ranking, filtering, and faceted search to enhance the user experience. - Vector Search
Vector search collections are optimized for similarity searches used in AI and machine learning applications. By comparing vector embeddings—dense representations of objects like images, text, or audio—this collection type supports recommendation systems, image recognition, and natural language processing. OpenSearch Serverless ensures the flexibility and scalability needed for these computationally demanding tasks.